Start your engines. Black Hat Booth #4140 has a Lambo.


-min.webp)
Most detection engineering programs were designed around a fundamentally human workflow. An analyst writes a rule, tunes it over weeks, and promotes it to production. Detection-as-code brought real improvements to this process: version control, peer review, CI/CD pipelines for rule deployment. The Sigma ecosystem gave us platform-agnostic rule sharing. Purple team programs gave us a way to validate coverage against real adversary behavior. These remain necessary. But the underlying model still assumes that a human evaluates the output of each detection in near-real time, and that the cost of a noisy rule is measured in analyst fatigue.
Before we continue, let’s define a few key terms because these terms get used loosely and the distinctions matter for what follows.
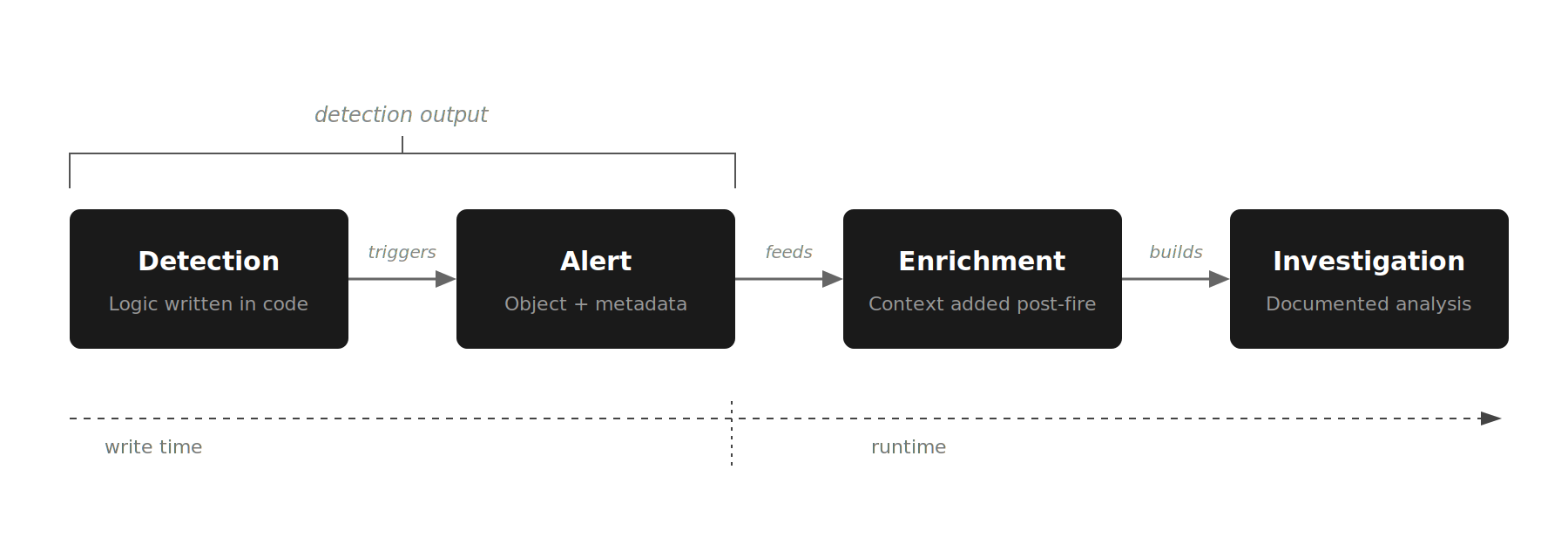
Detection engineers take raw signals from a host of sources, extract what is meaningful, package it with context, and ship it downstream to enable faster investigation. That is data engineering applied to security data, and it remains largely the same whether the downstream consumer is a Tier 1 analyst or an AI system.
The question this piece tries to answer is what happens to detection engineering best practices when the investigation layer is no longer a human analyst working a queue, but an AI system working every alert at machine speed.
When an AI SOC analyst sits between the alert and human decision-making, the calculus changes. Factors such as what the detection's output needs to carry, how tuning decisions get made, and what feedback the detection engineer gets back from the pipeline become critical.
A well-built AI SOC analyst queries connected data sources, enriches entities, and builds a documented investigation from whatever context is available in the alert. Richer detection output makes that process faster and less expensive. Several categories of metadata are worth thinking about.
Entity context. The identity, role, asset criticality, and recent behavioral baseline of the user or host associated with the alert. Two identical PowerShell command patterns mean different things when one runs on a developer workstation with a long history of script execution and the other runs on a finance team laptop that has never seen PowerShell before. UEBA platforms already compute these baselines, but the data is typically consumed during investigation, not embedded at detection time. Shifting that enrichment upstream, either in the detection logic or in a pre-processing pipeline, allows the AI to differentiate alerts that look identical at the surface level.
Technique classification at the sub-technique level. T1059.001 (PowerShell) and T1059.003 (Windows Command Shell) have different operational implications and different expected false positive profiles. Most detections already map to ATT&CK techniques. The additional work of mapping to sub-techniques gives the AI a stronger basis for cross-alert correlation and risk differentiation.
Confidence indicators that reflect how specific the detection logic actually is. This is a gap in current practice that deserves attention. A detection matching on a known malicious file hash (a high-specificity IOC) should be distinguished from a detection matching on a broad behavioral heuristic like "unusual outbound connection volume." Sigma's level field conflates two things: the severity of the potential finding and the confidence of the detection logic. These are separate dimensions. A behavioral heuristic might flag activity that would be critical if confirmed, but the detection itself has low specificity. An IOC match might flag activity that is only medium severity, but the detection is highly specific. The AI SOC analyst needs both signals to make a good decision.
The goal is to give the AI layer enough signal to differentiate between alerts that look identical at the surface level but carry very different risk profiles. The detection itself should surface that distinction, or at minimum provide the structured fields that allow the AI to compute it.
{{ebook-cta}}
The conventional lifecycle (hypothesis, implement, test, deploy, tune, retire) does not need to be replaced. Each stage needs to be adapted.
Start from threat intelligence or purple team findings, as always. But during the design phase, explicitly document what context the AI SOC analyst will need to triage and investigate alerts from this detection. If the detection depends on environmental context the AI SOC analyst cannot access (the user's department, the asset's patch status, the host's membership in a particular network segment), you have an integration gap to close before deployment.
Peer review in a detection-as-code workflow should now include the metadata, not just the logic. Are enrichment fields populated consistently? Does the confidence scoring reflect the actual specificity of the detection? The detection logic itself typically gets careful review. The metadata that shapes how the AI interprets the output often does not.
Purple team exercises already confirm whether detections fire on the right activity. In an AI-augmented SOC, extending that validation to confirm the AI correctly classifies the resulting alerts turns detection validation into pipeline validation.
Monitoring the AI's investigation disposition by detection rule over time gives detection engineers a layer of visibility into how their rules perform in production that has not previously existed. Which detections consistently produce escalations? Which produces investigations the AI closes as benign? That data, tracked per rule, is a feedback mechanism that most SOCs have never had.
And the nature of tuning shifts. The AI's investigation data exposes gaps in the detection's output where the rule didn't give the AI SOC analyst enough to work with. That is still tuning, but it is less about suppressing noise and more about understanding what makes a detection useful to the system consuming it.
There is also a category of tuning that has nothing to do with detection logic at all. The rule is correct, but the organization has business context that changes how the alert should be handled. A commercial VPN policy that applies to a subset of users. A set of service accounts that routinely trigger credential-based detections by design. These exceptions have always existed, and detection engineers have always built them; usually as brittle, hard-coded exclusions baked into the rule itself or maintained in unwieldy lookup tables. They are painful to build, painful to maintain, and they rot quickly.
An AI SOC analyst that can consume organizational context separately from detection logic offers a cleaner separation: the detection fires on the activity it was designed to detect, and the business context that determines whether that activity is expected lives in a layer the SOC can maintain without touching the rule. That means detection engineers stop being the bottleneck for every exception request, and the exceptions themselves become auditable rather than buried in rule logic where nobody reviews them.
Detections have a lifecycle. Techniques evolve, environments change, rules drift. In an AI-driven SOC, retirement decisions should factor in the AI layer's performance data. A detection that generates low-value signal for the AI, even if it is technically correct, may be consuming pipeline resources without contributing to outcomes. In most AI SOC pricing models, investigations carry direct cost, so this is not an abstract concern. Retire it or refactor it.
Traditional metrics like MTTD and false positive rate remain relevant, but they are no longer sufficient as standalone measures. You need metrics that capture the quality of the interaction between detection logic and the AI SOC analyst.
Investigation accuracy by detection. For each detection rule, measure the rate at which the AI's investigation conclusion and reasoning aligns with eventual human validation. The 2025 SANS/Anvilogic State of Detection Engineering survey found that teams increasingly want to measure detection quality by operational impact rather than ATT&CK coverage alone. A detection that consistently produces alerts the AI misclassifies (or is unable to classify with confidence) needs attention, regardless of its standalone accuracy.
Escalation precision. Track what percentage of AI-escalated alerts result in confirmed incidents, broken down by originating detection. This tells you which detections are producing signal the AI can act on effectively and which are generating noise that passes through investigation. It is the AI-era analogue of tracking true positive rates per rule, but measured at the point of analyst action rather than at the point of alert generation.
Coverage decay rate. Measure how detection effectiveness changes over time as attacker techniques evolve. AI-driven SOCs can accelerate this measurement by analyzing patterns in missed detections, but only if the detection layer provides enough structured context for meaningful post-incident analysis.
Context completeness. Audit a sample of alerts to assess whether the detection output includes sufficient metadata for the AI to make an informed investigation decision without requiring additional lookups. Every additional lookup the AI must perform, whether to a CMDB, an identity provider, or a threat intelligence platform, introduces latency and potential failure points. If the AI regularly compensates for missing detection metadata, that is a measurable gap.
Standard purple team engagements validate whether detections fire when techniques are executed. In an AI-augmented SOC, that validation has to extend to whether the AI SOC analyst correctly classifies what the detections produce. That means designing scenarios around the seams — alerts that might be deprioritized based on historical patterns, or attack chains where individual alerts look benign but are significant together. A simulation program that only validates detection coverage and not AI SOC analyst behavior is testing half the pipeline.
Several important questions remain unresolved, and intellectual honesty requires acknowledging them.
What is the optimal metadata schema for AI-consumed detection output? Entity context, technique classification, and confidence indicators are plausible categories, but the right level of granularity is unknown. The industry's movement toward OCSF is relevant here: organizations are adopting normalized schemas less for interoperability and more because normalization holds promise for building scalable AI systems on top of security data. Whether full OCSF adoption is worth the maintenance overhead is debatable. The direction of travel seems clear.
The right relationship between detection complexity and AI SOC analyst effectiveness is similarly unsettled. Whether detections should become simpler, acting as clean signal generators, or richer, doing more analytical work upstream, probably depends on the specific AI system's capabilities and the maturity of the detection program. The empirical data is still accumulating.
These are answerable questions. Answering them well requires operational data from real deployments at scale, and that work is underway.
The concern that an AI SOC analyst makes detection engineering less important gets the relationship backwards. In a traditional SOC, the impact of a well-engineered detection is limited by analyst capacity. Rules that fire correctly but never get triaged because the queue is too deep might as well not exist. In an AI-driven SOC, every detection gets investigated. Every alert produces structured investigation data. The detection engineer's work has a more direct line to operational outcomes than it has ever had, and the feedback loop for improving it is faster and more complete.
The highest-leverage work for most teams is auditing existing rule libraries for context density, investing in pipeline-level validation, and using the AI's investigation data to understand what their detections are actually doing in production. That last piece, closing the feedback loop, is the thing most detection programs have never had access to at scale.
The SOC is a queueing system. This eBook walks through the metrics that tell you whether yours is healthy
.png)

Daniel Martin
.svg)
Daniel Martin is a product leader at Prophet Security with over a decade of experience in cybersecurity product management. Before joining Prophet, he spent five years at Rapid7 leading product for InsightIDR's SIEM, XDR, and MDR capabilities. He's focused on building products that help security teams detect and respond to threats faster.