Gartner's Key Questions to Validate AI SOC Agents


-min.webp)
Suspicious login alerts are the most ignored category in most SOCs because the signal-to-noise ratio has been broken for years.
These are not just edge cases. This is what normal enterprise authentication looks like. Major identity providers will flag location-based anomalies, such as impossible travel anomalies, and most of those anomalies are policy-compliant users doing ordinary things from ordinary places. The alerts fire because the heuristic is simple: this location is new or anomalous. The investigation required to determine whether that matters is not simple at all.
Most teams handle this the way you would expect. They skim, they spot-check, they auto-close below a threshold, or they build suppression rules until the queue is tolerable. Anything to suppress the growing volume of alerts that are just users being users. All of those approaches are rational. None of them solve the underlying problem.
Adversaries know this, and they account for it. The real attacks use the same door as the false positives.
At Prophet Security, we’ve seen this abuse first hand. During a red team engagement at a customer environment, an attacker gains initial access through a ClickFix social engineering technique, a widely-abused method where the user is tricked into executing a clipboard payload, typically disguised as a browser or application fix. The payload dropped a malicious DLL that hooked into excel.exe at launch, establishing a command-and-control channel that blended into normal Office process behavior.
From that C2 foothold, the attacker obtained a valid session token, a Primary Refresh Token (PRT), using it to authenticate as the compromised user to multiple Microsoft services. With a valid PRT, the attacker did not need the user's password. They had a renewable key to the “front door”. They used it to access the Microsoft Azure CLI, move laterally through cloud resources, and operate with the privileges of a legitimate user session.
{{ebook-cta}}
This is not a novel technique. PRT abuse and session token replay have been documented extensively. Researchers and red teams have demonstrated that once an attacker obtains a PRT, they can refresh it from any network, any IP, any location, and the resulting sign-in events look like normal token-based authentication. The authentication never triggers a user-interactive login, so there is no MFA challenge to flag, no credential entry to key on, no brute force to rate-limit. The session just continues.
Here is what the customer's detection stack saw: nothing.
The only alert that fired across the entire kill chain was an “uncommon location OAuth2 login to Office 365”. One alert. The same alert type that fires hundreds or thousands of times a month at most organizations, and that most SOC teams have learned to treat as background noise.
If this was an edge case failure, it would be an interesting war story and nothing more. But it's not rare. It is structurally common, and most organizations only discover that after it is too late.
Whether it surfaces during a pentest or after a real breach, the moment lands the same way. The detection stack that leadership invested in, that the security team tuned and maintained, that vendors promised would catch exactly this kind of activity, did not fire. Or it fired once, on the nosiest alert type in the queue, and nobody had a reason to pull that thread. That is the moment that changes the conversation inside an organization. If the tooling missed a controlled exercise using known techniques, has an actual attacker already done the same thing? The organization was confident in its security posture two hours ago. Now it's not.
This is the quiet cost of treating detection as the finish line instead of the starting point. Detection stacks are not broken. They do what they are designed to do: fire on signatures, correlations, and heuristics. But modern attacks, especially those that abuse legitimate tokens and sessions, do not trigger signatures. They look like normal authenticated activity because, from the identity provider’s perspective, they are normal authenticated activity. The token is valid. The session is real. The device that was originally authenticated is compliant. The alert fired. What was missing was an investigation workflow deep enough to tell the difference between a legitimate user and an attacker holding a legitimate token.
There is another reason this alert would have been dismissed quickly under normal triage.
Because the attacker stole the session from a legitimate, enrolled device, the token carried the device compliance claims with it. When a SOC analyst pulls up a suspicious login and checks whether the device is compliant (managed, enrolled, passing health checks) that is often the fastest path to closing the alert as benign. A compliant device is one of the strongest signals an analyst has that the session belongs to a real employee on a real corporate machine.
In this case, the device was compliant. The user’s machine was enrolled, managed, and healthy. The attacker was not on that machine. They had hijacked the session from it. But the token they replayed still inherited the device compliance posture of the original authentication, because that is how token-based identity works. The compliance claim travels with the token, not with the network or device presenting it.
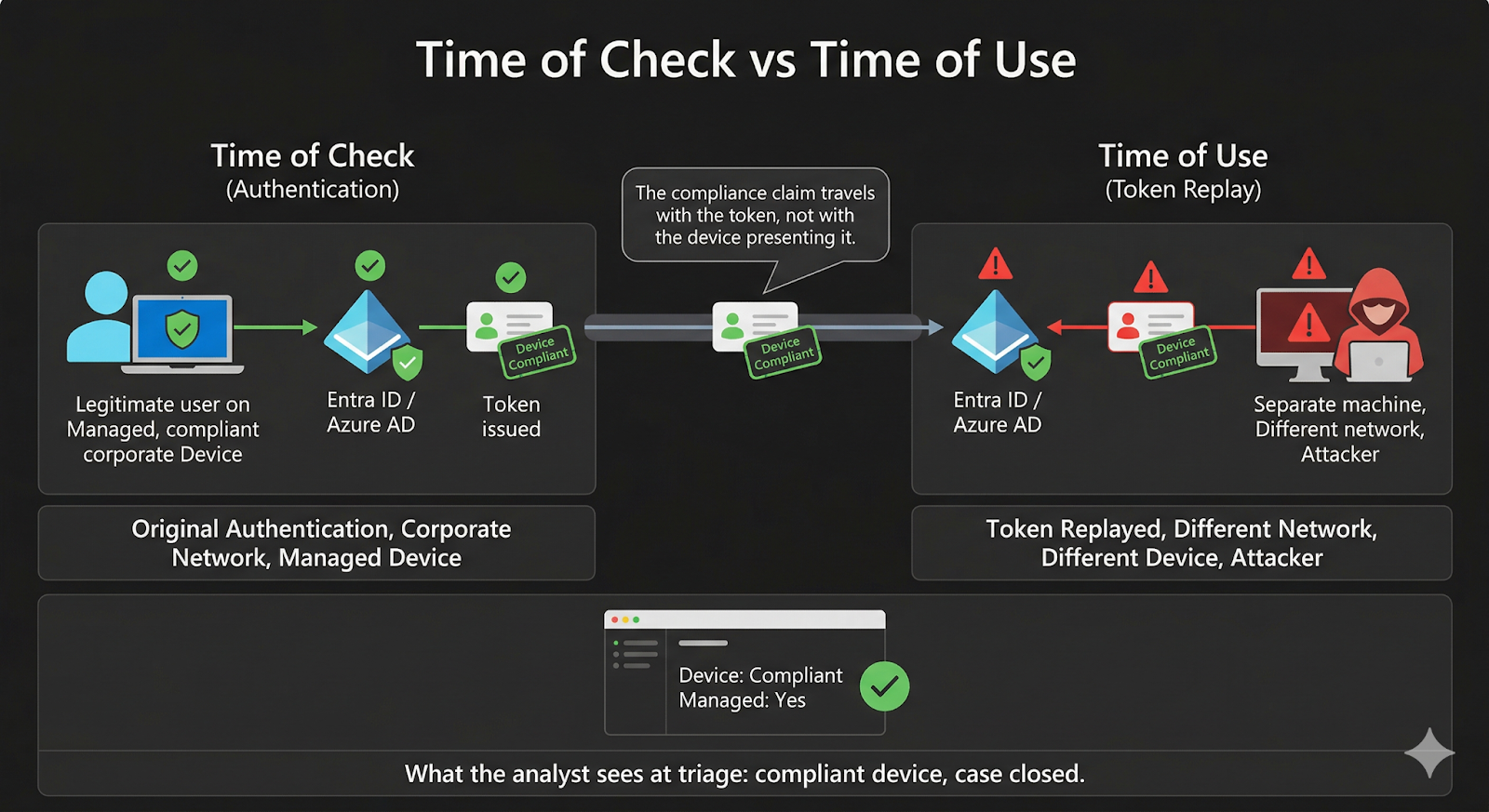
That means the most common SOC shortcut for resolving suspicious login alerts (check device compliance, confirm it is managed, close the ticket) would have led directly to a false negative. The alert would have been closed as a compliant user logging in from an unusual location. Case closed. Attacker still inside.
This is a structural limitation of how device compliance is evaluated at triage time. The compliance check answers the question “was the original device managed?” It does not answer the question “is the entity using this token right now the same entity that authenticated on that device?” Those are very different questions, and the gap between them is exactly where session hijacking lives.
The alert itself contained almost nothing useful. A user. A location. A timestamp. An application. That is the standard payload for a suspicious login alert, and it is the reason these alerts are expensive to investigate and easy to dismiss, especially when the device looks clean.
But when that alert was investigated with enough depth, pulling the surrounding sign-in telemetry, examining token types, analyzing IP behavior across the session window, and correlating user-agent patterns against historical baselines, the picture changed entirely.
The sign-in data showed PRT-based token refresh activity originating from multiple distinct IP addresses within a narrow time window. No fresh authentication, no password entry, no MFA challenge, appeared anywhere in the surrounding events. The IPs spanned different geographies and included infrastructure associated with commercial VPN providers and hosting platforms. The user-agent patterns shifted in ways inconsistent with the user’s historical behavior.
None of these individual data points would have generated an alert on their own. Token refreshes are normal. IP changes happen. User-agent variation exists. But the combination of multi-IP PRT activity, geographic diversity, absence of fresh authentication, and anonymizing infrastructure forms a pattern that is structurally inconsistent with a single legitimate user on a single device.
That pattern is what session hijacking looks like from the telemetry side. And it was visible in the data the entire time. No detection engine surfaced it. The device compliance check actively obscured it. The investigation found it. But the required depth of investigation to find it is dramatically different from what most SOCs are able to do today for these types of alerts.
Suspicious login alerts fire at enormous volume. At most organizations, 99 out of 100 are legitimate users on unfamiliar networks. SOC teams know this. Over time, analysts internalize the base rate. They develop pattern recognition not for the attack, but for the alert: check device compliance, confirm managed, close. That is not a failure of discipline. It is human cognition developing mental shortcuts, or heuristics, which allow them to respond to the noise. The 99 false positives train the analyst to expect the 100th will be false too.
An AI investigation layer does not have that problem. It does not experience alert fatigue. It does not need to develop heuristics to save precious brain energy. It runs the same depth of investigation on alert number 4,000 as it did on alert number 1, without degradation. But investigation depth is only as good as the framework it operates within.
When this pentest ran, the standard investigation pattern for suspicious login alerts, the same pattern used across the industry, treated device compliance as a strong signal of session legitimacy. That was reasonable. It was also incomplete. The telemetry to distinguish a legitimate session from a replayed token was present in the environment. But the investigation framework had not yet been built to examine it.
After the engagement, we mapped the red team's activity against the available telemetry and closed the gap. The platform's investigation framework was expanded so that device compliance at the start of a session is no longer the end of the analysis.
This is the compounding advantage. A detection engine cannot update its own logic. A human analyst can learn, but still has to apply that knowledge manually against alert volume that guarantees most of the queue will never get that depth. An AI investigation layer absorbs the new framework and applies it to every alert, at full depth, without fatigue, and without the cognitive erosion that comes from seeing the same noisy alert type thousands of times.
This is the distinction that matters: the detection layer did its job. It flagged an anomaly. But investigating that anomaly with the depth required to catch a session hijack, full session telemetry, token-type analysis, IP enrichment, geo-correlation, user-agent history, behavioral baselining, takes real time. Apply that to every suspicious login alert and your team will not have the cycles to do anything else. That is not a problem that staffing alone can solve because it is structural. It is the same dynamic that breaks DLP programs, phishing response workflows, and most alert-driven security operations. Detection produces volume. Investigation requires depth. The gap between the two is where risk lives.
When the session hijacking pattern was identified and the investigation methodology was refined, tuning what telemetry to pull, what thresholds to apply, what behavioral signals to weight, something else became clear.
The methodology was not specific to the pentest. It was a general-purpose investigation pattern for any suspicious login alert. Multi-IP PRT behavior, geographic diversity in token refresh activity, absence of fresh authentication, presence of anonymizing infrastructure, user-agent inconsistencies. These are not signatures of one attack. They are structural indicators of token theft and session replay regardless of how the token was obtained. This is the difference between investigating at the indicator level, where IOCs are brittle and expire, and investigating at the technique level, where the behavioral pattern holds regardless of the tooling behind it.
That means every future suspicious login alert can be investigated against the same behavioral framework. Not just the ones that happen to coincide with a known pentest or a confirmed incident. All of them. The noisy ones. The ones that get auto-closed. The ones nobody has time to look at.
This shifts the value proposition of the alert entirely. A suspicious login alert is no longer a low-fidelity signal that might indicate something but probably does not. It becomes the trigger for a structured investigation that can actually distinguish a VPN user in a hotel from an attacker replaying a stolen session token, even when the stolen token looks like it came from a compliant device.
There is a second-order effect here that is worth naming directly.
Every alert that gets investigated deeply, whether it turns out to be benign or malicious, produces information about what normal looks like and what abnormal looks like in that specific environment
That information feeds back into investigation prioritization, detection tuning, and policy refinement. It is not threat hunting in the traditional sense. Nobody is starting from a hypothesis and searching for indicators. It is closer to continuous validation: using the AI investigation layer to confirm, at scale, that the alerts the SOC is closing actually are benign, and surfacing the ones that are not.
The pentest happened to be the forcing function. The capability it exposed is broader: an investigation layer that learns from every engagement, closes its own gaps, and operates at the speed and scale of the alert queue, not just at the speed of the analyst staffed to work it.
Security teams do not need another detection engine that fires on the same suspicious login and adds one more item to the same queue.
What they need is the ability to properly investigate what detection already sees. Quickly enough to matter, deeply enough to distinguish real attacks from policy-compliant noise, and consistently enough that the answer does not depend on which analyst happens to pick up the ticket or whether they thought to look past the device compliance check.
The pentest proved that in specific, uncomfortable terms. Every purpose-built detection system either missed the attack entirely or surfaced it as a generic anomaly indistinguishable from the thousands of benign alerts that fire alongside it.
The only signal that fired was the noisiest, lowest-fidelity alert type in the stack. The fastest triage shortcut would have confirmed the attacker as legitimate. And inside the surrounding telemetry that the alert pointed to, the data that nobody had time to look at, was everything needed to identify a compromised session.
The first time, the investigation layer missed it. The second time, it will not. That is the difference between a rigid investigation playbook and a system that learns how to improve its investigations.
But a system that learns still needs something to learn from. No model independently concluded what separates a compromised session from a legitimate one in sign-in telemetry. A security practitioner did. Someone who has worked on real incidents, who understands what attacker behavior looks like in production, and who can tell the difference between a pattern that matters and one that does not. The AI did not replace that expertise. It gave it reach. What one practitioner identified from a single engagement, the platform now applies to every alert, at full depth, without fatigue or degradation. The scaling mechanism is artificial. The intelligence behind it is not.
Detection found the door. Investigation found the intruder. The expertise to know what to look for came from the people who understand how attacks actually work. The future of security operations is making sure that expertise scales.
Request a demo today to see how Prophet AI investigates your alerts.
The SOC is a queueing system. This eBook walks through the metrics that tell you whether yours is healthy
.png)

Eric Jarlsberg
.svg)
Determined, organized, and hardworking leader with a passion for Cybersecurity, critical thinking and problem solving that is looking to drive results in offensive or defensive security solutions.